10 Essential Spark Interview Questions *
Toptal提供了最好的Spark开发人员和工程师可以回答的基本问题. 在我们社区的推动下,我们鼓励专家提交问题并提供反馈.
Hire a Top Spark Developer NowInterview Questions
Describe the following code and what the output will be.
case class User(userId: Long, userName: String)
case类UserActivity(userId: Long, activity类型id: Int, timestampEpochSec: Long)
val LoginActivityTypeId = 0
val LogoutActivityTypeId = 1
private def readUserData(sparkSession: sparkSession): RDD[User] = {
sparkSession.sparkContext.parallelize(
Array(
User(1, "Doe, John"),
User(2, "Doe, Jane"),
User(3, "X, Mr."))
)
}
private def readUserActivityData(sparkSession: sparkSession): RDD[UserActivity] = {
sparkSession.sparkContext.parallelize(
Array(
UserActivity(1, LoginActivityTypeId, 1514764800L),
UserActivity(2, LoginActivityTypeId, 1514808000L),
UserActivity(1, LogoutActivityTypeId, 1514829600L),
UserActivity(1, LoginActivityTypeId, 1514894400L))
)
}
def calculate(sparkSession: SparkSession): Unit = {
val userRdd: RDD[(Long, User)] =
readUserData(sparkSession).map(e => (e.userId, e))
val userActivityRdd: RDD[(Long, UserActivity)] =
readUserActivityData(sparkSession).map(e => (e.userId, e))
val result = userRdd
.leftOuterJoin(userActivityRdd)
.filter(e => e._2._2.isDefined && e._2._2.get.activityTypeId == LoginActivityTypeId)
.map(e => (e._2._1.userName, e._2._2.get.timestampEpochSec))
.reduceByKey((a, b) => if (a < b) a else b)
result
.foreach(e => println(s"${e._1}: ${e._2}"))
}
The main method, calculate, reads two sets of data. (在本例中,它们是从一个常量内联数据结构中提供的,该数据结构使用 parallelize.)应用于它们的映射将它们转换成元组,每个元组由a组成 userId and the object itself. The userId is used to join the two datasets.
连接的数据集由所有登录活动的用户过滤. It is then transformed into a tuple consisting of userName and the event timestamp.
这最终减少到每个用户的第一个登录条目,并写入控制台.
The result will be:
Doe, John: 1514764800
Doe, Jane: 1514808000
下面的代码提供了两个准备好的数据框架,结构如下:
DF1: userId, userName
DF2: userId, pageId, timestamp, eventType
添加代码以连接两个数据帧并计算每个数据帧的事件数 userName. It should output in the format userName; totalEventCount and only for users that have events.
def calculate(sparkSession: SparkSession): Unit = {
val UserIdColName = "userId"
val UserNameColName = "userName"
val CountColName = "totalEventCount"
val userRdd: DataFrame = readUserData(sparkSession)
userActivityRdd: DataFrame = readUserActivityData(sparkSession)
val result = userRdd
.repartition(col(UserIdColName))
// ???????????????
.select(col(UserNameColName))
// ???????????????
result.show()
}
The complete code should look like this:
def calculate(sparkSession: SparkSession): Unit = {
val UserIdColName = "userId"
val UserNameColName = "userName"
val CountColName = "totalEventCount"
val userRdd: DataFrame = readUserData(sparkSession)
userActivityRdd: DataFrame = readUserActivityData(sparkSession)
val result = userRdd
.repartition(col(UserIdColName))
.join(userActivityRdd, UserIdColName)
.select(col(UserNameColName))
.groupBy(UserNameColName)
.count()
.withColumnRenamed("count", CountColName)
result.show()
}
The join expression can take different kinds of parameters. The following alternatives produce the same result:
.join(userActivityRdd,UserIdColName, "inner")
.join(userActivityRdd, Seq(UserIdColName))
.join(userActivityRdd, Seq(UserIdColName), "inner")
将“left”作为最后一个参数将返回错误的结果(没有事件的用户将被包括在内), showing an event count of 1).
传递“right”作为最后一个参数将返回正确的结果,但会在语义上产生误导.
.groupBy(UserNameColName)
This is required. Without it, the total number of rows would be counted and result would be a Long instead of a DataFrame (so the code wouldn’t even compile, since the show() method does not exist for Long.)
.count()
This is the actual aggregation that adds a new column (count) to the DataFrame.
.withColumnRenamed("count", CountColName)
This renames the count column to totalEventCount, as requested in the question.
下面的代码注册一个用户定义函数(UDF)并在查询中使用它. (The general business logic is irrelevant to the question.)代码有什么问题,可能会导致整个集群崩溃, and how can it be solved?
(Hint: It has to do with the usage of the categoryNodesWithChildren Map variable.)
def calculate(sparkSession: SparkSession): Unit = {
val UserIdColumnName = "userId"
val CategoryIdColumnName = "categoryId"
val NumActionsColumnName = "numActions"
val OtherCategoryIdColumnName = "otherCategoryId"
val OtherNumActionsColumnName = "otherNumActions"
val categoryNodesWithChildren: Map[Int, Set[Int]] =
Map(0 -> Set(1, 2, 3),
1 -> Set(4, 5),
2 -> Set(6, 7),
3 -> Set(8),
7 -> Set(9, 10)
)
sparkSession.udf.register("isChildOf", (nodeId: Int, parentNodeId: Int) =>
nodeId != parentNodeId && categoryNodesWithChildren.getOrElse(nodeId, Set[Int]()).contains(parentNodeId))
val userCategoryActions = readUserCategoryActions(sparkSession)
val otherUserCategoryActions = userCategoryActions
.select(
col(UserIdColumnName),
col(CategoryIdColumnName).alias(OtherCategoryIdColumnName),
col(NumActionsColumnName).alias(OtherNumActionsColumnName)
)
val joinedUserActions = userCategoryActions
.join(otherUserCategoryActions, UserIdColumnName)
.where("!(isChildOf(categoryId,otherCategoryId)或isChildOf(otherCategoryId,categoryId))")
.groupBy(UserIdColumnName, CategoryIdColumnName, OtherCategoryIdColumnName)
.sum(OtherNumActionsColumnName)
.withColumnRenamed (s“sum (OtherNumActionsColumnName美元)”,OtherNumActionsColumnName)
joinedUserActions.show()
}
注册UDF的那行应该替换为下面的代码片段:
def calculate(sparkSession: SparkSession): Unit = {
...
val categoryNodesWithChildrenBC = sparkSession.sparkContext.broadcast(categoryNodesWithChildren)
sparkSession.udf.register("isChildOf", (nodeId: Int, parentNodeId: Int) =>
nodeId != parentNodeId && categoryNodesWithChildrenBC.value.getOrElse(nodeId, Set[Int]()).contains(parentNodeId))
...
}
第一种方法的问题是,它使用了驱动程序应用程序中不可用的变量 per se on the worker nodes. Spark will fetch the variable (meaning, the whole Map) from the master node each time the UDF is called. 这可能导致主服务器的负载非常高,整个集群可能变得无响应.
对代码的修改会将变量的副本发送(广播)到每个工作节点,在这些节点中,变量可以作为对象进行访问 org.apache.spark.broadcast object that holds the actual Map.
Apply to Join Toptal's Development Network
and enjoy reliable, steady, remote Freelance Spark Developer Jobs
Give a general overview of Apache Spark. How is the framework structured? What are the main modules?
The basic structure of a Spark-cluster:
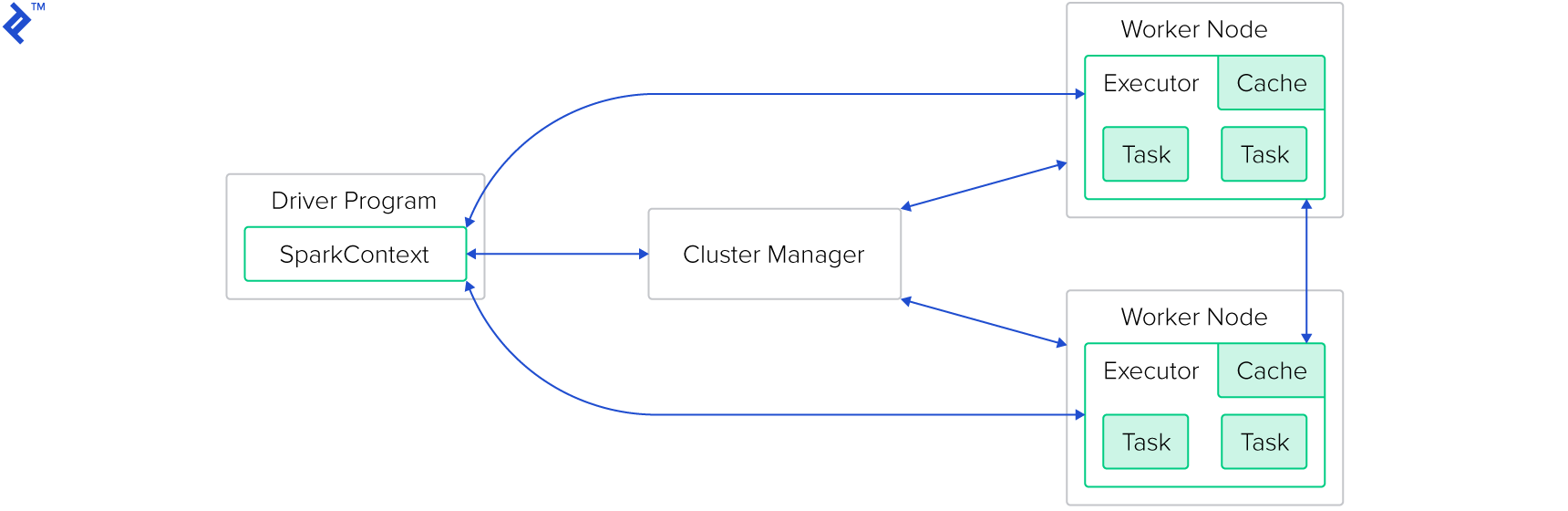
集群管理器不是Spark框架本身的一部分——尽管Spark自带了它自己的框架, this one should not be used in production. Supported cluster managers are Mesos, Yarn, and Kybernetes.
驱动程序是在Spark Master上执行的Java、Scala或Python应用程序.
As part of the program, some Spark framework methods will be called, which themselves are executed on the worker nodes.
每个工作节点可能运行多个执行器(按配置:通常每个可用CPU内核一个执行器). 每个执行程序都将从要执行的调度器接收一个任务.
The modules of Apache Spark run directly on top of its core:

Apache Spark (Core)
Spark由一个核心框架组成,该框架管理数据的内部表示,包括:
- serialization
- memory allocation
- caching
- increasing resilience by storing intermediate snapshots on disk
- automatic retries
- data exchange (shuffling) between worker nodes
- etc.
It also provides a bunch of methods to transform data (like map and reduce). 所有这些方法都适用于弹性分布式数据集(RDD).
Spark自动识别单个步骤之间的依赖关系,从而知道哪些步骤可以并行执行.
This is accomplished by building a directed acyclic graph (DAG), 这也意味着转换不会立即执行, but when action functions are called.
所以基本上,方法可以分为两种类型:RDD转换和操作.
These are RDD transformations:
map(func)flatMap()filter(func)mapPartitions(func)mapPartitionWithIndex()union(dataset)intersection(dataset)distinct()groupByKey()reduceByKey(func, [numTasks])sortByKey()join()coalesce()
And these are RDD actions:
count()collect()take(n)top()countByValue()reduce()fold()aggregate()foreach()
在Spark UI web界面中可以查看正在运行的作业的DAG. 它还显示挂起的作业、任务列表以及当前的资源使用和配置.
如果配置了历史服务器,还可以查看已完成(或失败)作业的大多数信息.
Spark SQL
This is an abstraction of Spark’s core API. Whereas the core API works with RDD, and all transformations are defined by the developer explicitly, Spark SQL represents the RDD as so-called DataFrames. The DataFrame API is more like a DSL that looks like SQL.
开发人员甚至可以通过将DataFrame注册为已命名的内存表来更加抽象RDD. 然后可以像使用SQL查询关系数据库中的表一样查询该表.
Spark Streaming
它可以轮询分布式日志,如Apache Kafka或Amazon Kinesis(以及其他一些消息传递系统), like ActiveMQ) to process the messages in micro-batches. (几乎)所有Spark批处理作业可用的功能也可以应用到Spark Streaming提供的RDD上.
MLlib
MLlib提供了在一般数据分析(如聚类和回归)和机器学习中常用的高级算法. It provides the functionality to define pipelines, train models and persist them, and read trained models to apply them to live data.
GraphX
这允许您将RDD表示为图(节点通过边连接)并对其执行一些基本的图操作. Currently (only) three more advanced algorithms are provided: PageRank, ConnectedComponents, and TriangleCounting.
完成缺失的SQL查询,返回基于示例数据的结果:
case class User(userId: Long, userName: String)
case类UserActivity(userId: Long, activity类型id: Int, timestampEpochMs: Long)
val LoginActivityTypeId = 0
val LogoutActivityTypeId = 1
private def readUserData(sparkSession: sparkSession): DataFrame = {
sparkSession.createDataFrame(
sparkSession.sparkContext.parallelize(
Array(
User(1, "Doe, John"),
User(2, "Doe, Jane"),
User(3, "X, Mr."))
)
)
}
private def readUserActivityData(sparkSession: sparkSession): DataFrame = {
sparkSession.createDataFrame(
sparkSession.sparkContext.parallelize(
Array(
UserActivity(1, LoginActivityTypeId, 1514764800000L),
UserActivity(2, LoginActivityTypeId, 1514808000000L),
UserActivity(1, LogoutActivityTypeId, 1514829600000L),
UserActivity(1, LoginActivityTypeId, 1514894400000L))
)
)
}
def calculate(sparkSession: SparkSession): Unit = {
val UserTableName = "user"
val UserActivityTableName = "userActivity"
val userDf: DataFrame = readUserData(sparkSession)
readUserActivityData(sparkSession)
userDf.createOrReplaceTempView(UserTableName)
userActivityDf.createOrReplaceTempView(UserActivityTableName)
val result = sparkSession
.sql(s"SELECT ...")
result.show()
}
The output should be this:
| userName | firstLogin |
|---|---|
| Doe, John | 1514764800000 |
| Doe, Jane | 1514808000000 |
The missing SQL should look something like this:
val result = sparkSession
.sql(s"SELECT u.userName, MIN(ua.timestampEpochMs) AS firstLogin " +
s"FROM $UserTableName u " +
s"JOIN $UserActivityTableName ua ON u.userId=ua.userId " +
s"WHERE ua.activityTypeId=$LoginActivityTypeId " +
s"GROUP BY u.userName")
(The $ notation是Scala的一个特性,用于替换字符串中的表达式,而表名也可能是“硬编码”的. 请注意,永远不要对用户提供的变量这样做,因为这会使代码容易受到注入漏洞的攻击.)
请突出显示以下代码的哪一部分将在主机上执行, and which will be run on each worker node.
val formatter: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy/MM")
defgeteventcountonweekdayspermonth (data: RDD[(LocalDateTime, Long)]): Array[(String, Long)] = {
val result = data
.filter(e => e._1.getDayOfWeek.getValue < DayOfWeek.SATURDAY.getValue)
.map(mapDateTime2Date)
.reduceByKey(_ + _)
.collect()
result
.map(e => (e._1.format(formatter), e._2))
}
private def mapDateTime2Date(v: (LocalDateTime, Long)): (LocalDate, Long) = {
(v._1.toLocalDate.withDayOfMonth(1), v._2)
}
The call of this function is performed by the driver application. The assignment to the result 值是DAG的定义,包括它的执行,由 collect() call. All parts of this (including the logic of the function mapDateTime2Date) are executed on the worker nodes.
The resulting value that is stored in result 是在主服务器上收集的数组,因此对该值执行的映射在主服务器上运行.
Compare Spark Streaming to Kafka Streams and Flink. Highlight the differences and advantages of each technology, 以及每种流处理框架最适合哪些用例.
下表概述了每个框架的一些特征. 何时使用哪个框架并不总是有一个明确的答案. 特别是因为他们经常在不重要的细节上有所不同.
But it’s important to understand:
- Kafka Streams只是一个库(没有额外的基础设施组件), 但是它有责任部署和扩展流应用程序).
- 在低延迟流处理方面,Flink是目前最优越/功能最丰富的框架(当流被用作服务之间的实时核心通信时,这一点很重要)。.
- Spark的主要优点是整个现有的生态系统,包括MLlib/GraphX抽象,部分代码可以被批处理和流处理功能重用.
| Flink | Kafka Streams | Spark Streaming | |
|---|---|---|---|
| Deployment | A framework that also takes care of deployment in a cluster | A library that can be included in any Java program. Deployment depends how the Java application is deployed. | A framework that also takes care of deployment in a cluster |
| Life cycle | Stream processing logic is run as a job in the Flink cluster | 流处理逻辑作为“标准”Java应用程序的一部分运行 | Stream processing logic is run as a job in the Spark cluster |
| Responsibility | Dedicated infrastructure team | Application developer | Dedicated infrastructure team |
| Coordination | Flink master (JobManager), part of the streaming program | 利用Kafka集群进行协调、负载平衡和容错 | Spark Master |
| Source of continuous data | Kafka, File Systems, other message queues | Kafka only | Common streaming platforms like Kafka, Flume, Kinesis, etc. |
| Sink for results | 使用Flink Sink API的实现可用的任何存储 | 使用Kafka Connect API实现Kafka Sink的Kafka或任何其他存储 | File and Kafka as a predefined sink, 使用forEach-sink的任何其他目的地(手动实现) |
| Bounded and unbounded data streams | Unbounded and bounded | Unbounded | Unbounded (bounded using Spark Batch jobs) |
| Semantical guarantees | Exactly once for internal Flink state; end-to-end exactly once with selected sources and sinks (e.g., Kafka to Flink to HDFS); at least once when Kafka is used as a sink | Exactly once, end-to-end with Kafka | Exactly once |
| Stream processing approach | Single record | Single record | Micro-batches |
| State management | Key-value storage, transparent to the developer | No, must be implemented manually | No, stateless by nature |
| Feature set | 丰富的特性集,包括事件时间(相对于处理时间)、滑动窗口和水印 | Simple features set to aggregate in tumbling windows | 广泛的功能集,但缺乏Flink提供的一些更高级的功能 |
| Low latency | Yes | Yes | No |
| Example of when to choose as stream processor | 建立一个新的事件驱动的体系结构,该体系结构需要高级流处理特性和低延迟要求 | 应该使用现有Kafka事件流的JVM应用程序 | 当Spark已经用于批处理并且不强制要求低延迟时,添加流处理 |
GraphX库使用的元素是什么,它们是如何从RDD创建的? Complete the following code to calculate the page ranks.
def calculate(sparkSession: SparkSession): Unit = {
val pageRdd: RDD[(???, Page)] =
readPageData(sparkSession)
.map(e => (e.pageId, e))
.cache()
val pageReferenceRdd: RDD[???[PageReference]] = readPageReferenceData(sparkSession)
val graph = Graph(pageRdd, pageReferenceRdd)
val PageRankTolerance = 0.005
val ranks = graph.???
ranks.take(1000)
.foreach(println)
}
The result will be a list of tuples that looks like this:
(1,1.4537951595091907)
(2,0.7731024202454048)
(3,0.7731024202454048)
def calculate(sparkSession: SparkSession): Unit = {
val pageRdd: RDD[(VertexId, Page)] =
readPageData(sparkSession)
.map(e => (e.pageId, e))
.cache()
val pageReferenceRdd: RDD[Edge[PageReference]] = readPageReferenceData(sparkSession)
val graph = Graph(pageRdd, pageReferenceRdd)
val PageRankTollerance = 0.005
val ranks = graph.pageRank(PageRankTollerance).vertices
ranks.take(1000)
.foreach(println)
}
A graph consists of Vertex objects and Edge objects that are passed to the Graph object as RDDs of type RDD[VertexId, VT] and RDD[Edge[ET]] (where VT and ET 是否有任何用户定义的类型应该与给定相关联 Vertex or Edge). The constructor of the Edge type is Edge[ET](srcId: VertexId, dstId: VertexId, attr: ET).
The type VertexId is basically an alias for Long.
您有一个包含10个节点的集群,每个节点上有24个CPU内核可用.
The following code works but might crash on large data sets, 或者至少不会利用集群的全部处理能力. Which is the problematic part and how would you adapt it?
def calculate(sparkSession: SparkSession): Unit = {
val NumNodes = 10
val userActivityRdd: RDD[UserActivity] =
readUserActivityData(sparkSession)
.repartition(NumNodes)
val result = userActivityRdd
.map(e => (e.userId, 1L))
.reduceByKey(_ + _)
result
.take(1000)
}
The repartition 语句生成10个分区(无论从任何地方加载分区时是多还是少). 对于庞大的数据集,这些变量可能会变得非常大,并且可能无法容纳为一个执行器分配的内存.
Also, only one partition can be allocated per executor. This means, 240个执行器中只有10个被使用(10个节点和24个核心), each running one executor).
If the number is chosen too high, 调度器管理分区的开销会增加并降低性能. 在某些情况下,对于非常小的分区,它甚至可能超过执行时间本身.
The recommended number of partitions is between two to three times the number of executors. In our case, 600 = 10 x 24 x 2.5 would be an appropriate number of partitions.
Spark MLlib has two basic components: Transformers and Estimators.
A Transformer reads a DataFrame and returns a new DataFrame with a specific transformation applied (e.g. new columns added). An Estimator is some machine learning algorithm that takes a DataFrame to train a model and returns the model as a Transformer.
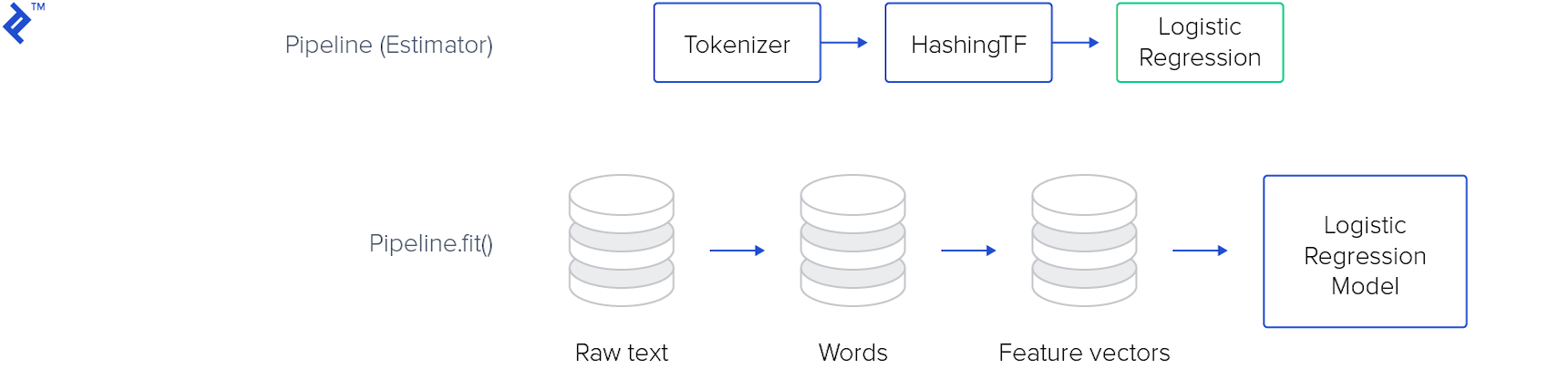
Spark MLlib允许您将多个转换组合到一个管道中 apply complex data transformations:
The following image shows such pipeline for training a model:
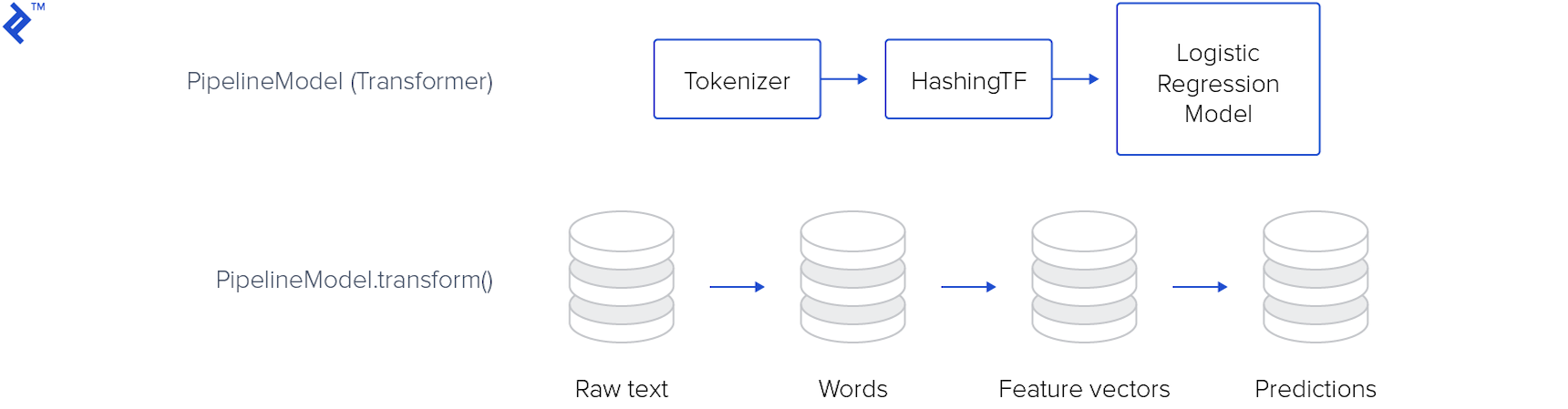
The model produced can then be applied to live data:
There is more to interviewing than tricky technical questions, so these are intended merely as a guide. 并不是每一个值得雇佣的“A”候选人都能回答所有的问题, nor does answering them all guarantee an “A” candidate. At the end of the day, hiring remains an art, a science — and a lot of work.
Why Toptal
Tired of interviewing candidates? Not sure what to ask to get you a top hire?
Let Toptal find the best people for you.
Hire a Top Spark Developer NowOur Exclusive Network of Spark Developers
Looking to land a job as a Spark Developer?
Let Toptal find the right job for you.
Apply as a Spark DeveloperJob Opportunities From Our Network
Submit an interview question
提交的问题和答案将被审查和编辑, and may or may not be selected for posting, at the sole discretion of Toptal, LLC.
Looking for Spark Developers?
Looking for Spark Developers? Check out Toptal’s Spark developers.

Steve Fox
Freelance Spark Developer
Steve是一名经过认证的AWS解决方案架构师,拥有大数据和机器学习专业认证. He has a diverse background, and experience architecting, building, and operating big data machine learning applications in AWS. Steve has held roles from technical contributor to CTO and CEO.
Show More
Andreas Bollig
Freelance Spark Developer
With a Ph.D. 在电气工程方面有丰富的机器学习应用开发经验, Andreas spans the entire AI value chain, 从用例识别和可行性分析到定制统计模型和应用程序的实现. Throughout projects, 他一直专注于解决手头的业务问题,并从数据中创造价值.
Show More
Luigi Crispo
Freelance Spark Developer
Luigi是一位经验丰富的云和领导力专家,在各种环境中拥有超过二十年的专业经验. 他对技术和价值驱动的项目充满热情,并且具有很强的适应能力. Luigi已经直接参与了一些推动数字时代的领导者的重大行业转型浪潮.
Show MoreToptal Connects the Top 3% of Freelance Talent All Over The World.
Join the Toptal community.